Attacking Android Binder: Analysis and Exploitation of CVE-2023-20938
Table of Contents
At OffensiveCon 2024, the Android Red Team gave a presentation (slides) on finding and exploiting CVE-2023-20938, a use-after-free vulnerability in the Android Binder device driver. This post will provide technical details about this vulnerability and how our team used it to achieve root privilege from an untrusted app on a fully up-to-date (at the time of exploitation) Android device. This vulnerability affected all Android devices using GKI kernel versions 5.4 and 5.10.
This vulnerability is fixed and the patches were released as part of the Android Security Bulletin–February 2023 and July 2023 (more details in the remediation section of the blog).
This is the first post of a multi-part series where we discuss our journey into Binder:
- Part 1: Attacking Android Binder: Analysis and Exploitation of CVE-2023-20938
- Part 2: Binder Internals
Binder is the primary inter-process communication (IPC) channel on Android. It supports a variety of features such as passing file descriptors and objects containing pointers across process boundaries. It is composed of userspace libraries (libbinder and libhwbinder) provided by the Android platform and a kernel driver in the Android Common Kernel. Therefore, it provides a common IPC interface for Java and native code which can be defined in AIDL. The term “Binder” is commonly used to refer to many parts of its implementation (there is even a Java class called Binder in Android SDK), but in this post we will use the term “Binder” to refer to the Binder device driver unless otherwise stated.
All untrusted apps on Android are sandboxed and inter-process communication mostly occurs through Binder. Meanwhile, Chrome’s renderer process on Android is assigned the isolated_app SELinux context, which is more restrictive than untrusted apps. Despite that, it also has access to Binder and a limited set of Android services. Therefore, Binder presents a wide attack surface because it is accessible by default to every untrusted and isolated app.
Here is a list of recent exploits that have exploited vulnerabilities in Binder to achieve root privilege:
- CVE-2019-2025 Waterdrop: slides, video
- CVE-2019-2215 Bad Binder: blog, video
- CVE-2020-0041: blog
- CVE-2020-0423 Typhoon Mangkhut: slides, video
- CVE-2022-20421 Bad Spin: whitepaper, video
To provide high performance IPC, Binder consists of an extremely complex object lifetime, memory management, and concurrent threading model. To give a sense of this complexity, we counted three different types of concurrency synchronization primitives (5 locks, 6 reference counters, and a few atomic variables) all being used in the same 6.5k line file implementing the driver. The locking in Binder is also extremely fine-grained for performance reasons, further increasing the complexity of the code.
There have been a number of successful attacks against Binder in recent years by leveraging several security issues, primarily caused by use-after-free bugs. These bugs arise from various root causes, including improper cleanup logic (CVE-2019-2215 and CVE-2022-20421), data races (CVE-2020-0423), and intra-object out-of-bounds access (CVE-2020-0041). This blog provides information on a UAF issue which is a result of improper clean up implementation while processing a Binder transaction which leads to a refcounting error.
This section will describe how a userspace program interacts with Binder. This section provides a quick overview of what Binder is and how userspace applications interact with it on Android to help illustrate some concepts in Binder. However, if you are already familiar with Binder, feel free to skip this and go to the Vulnerability section.
Developing programs to perform IPC via Binder is somewhat different from using other types of sockets (e.g. such as network sockets, etc).
Every client first open the Binder device and create a memory mapping using the returned file descriptor:
int fd = open("/dev/binder", O_RDWR, 0);
void *map = mmap(NULL, 4096, PROT_READ, MAP_PRIVATE, ctx->fd, 0);
This memory will be used for the Binder driver’s memory allocator, which is used to store all of the incoming transaction data. This mapping is read-only for the client, but writable by the driver.
Instead of calling the send and recv syscalls, clients perform most IPC interactions by sending the BINDER_WRITE_READ ioctl to the Binder driver. The argument to the ioctl is a struct binder_write_read object:
struct binder_write_read bwr = {
.write_size = ...,
.write_buffer = ...,
.read_size = ...,
.read_buffer = ...
};
ioctl(fd, BINDER_WRITE_READ, &bwr);
The write_buffer pointer field points to a userspace buffer containing a list of commands from the client to the driver. Meanwhile, the read_buffer pointer field points to a userspace buffer in which the Binder driver will write commands from the driver to the client.
Note: The motivation for this design is that a client can send a transaction and then wait for a response with one ioctl syscall. In contrast, IPC with sockets requires two syscalls,
sendandrecv.
The diagram below shows the data involved when sending a transaction to a client linked to the Ref 0 (target.handle) and the transaction contains a Node object (BINDER_TYPE_BINDER):
The write_buffer points to a buffer that contains a list of BC_* commands and their associated data. The BC_TRANSACTION command instructs Binder to send a transaction struct_binder_transaction_data. The read_buffer points to an allocated buffer that will be filled by Binder when there are incoming transactions.
The struct binder_transaction_data contains a target handle and two buffers, buffer and offsets. The target.handle is the Ref ID associated with the recipient, which we will discuss how it is created later. The buffer points to a buffer containing a mix of Binder objects and opaque data. The offsets points to an array of offsets at which every Binder object is located in the buffer. The recipient will receive a copy of this struct binder_transaction_data in the read_buffer after it performs a read with the BINDER_WRITE_READ ioctl.
Users can send a Node by including a struct flat_binder_object with the type field set to BINDER_TYPE_BINDER in the transaction data. The Node is a type of Binder object, which we will discuss more in the next section.
Binder uses objects such as a Node and a Ref to manage communication channels between processes.
If a process wants to allow another process to talk to it, it sends a Node to that process. Binder then creates a new Ref in the target process and associates it with the Node, which establishes a connection. Later, the target process can use the Ref to send a transaction to the process that owns the Node associated with the Ref.
The image above illustrates the steps on how App A establishes a connection for App B with itself, so App B can send transactions to App A to perform RPC calls.
The steps are as follows:
- App A sends a transaction to App B containing a Node with 0xbeef as ID. The transaction is similar to the one shown above and the Node is represented by the
struct flat_binder_objectdata. - Binder associates the Node 0xbeef with App A internally and initializes a reference counter to keep track of how many Refs are referencing it. In the actual implementation, there are 4 reference counters in the underlying Node data structure (
struct binder_node), which we will cover later. - Binder creates a Ref 0xbeef that belongs to App B internally and it references App A’s Node 0xbeef. This step increments the Node 0xbeef refcount by 1.
- Now, App B can send transactions to App A by using 0xbeef as the
target.handlein itsstruct binder_transaction_datain future. When Binder processes the transaction sent by B, it can find out that the Ref 0xbeef references App A’s Node 0xbeef and send the transaction to App A.
One might ask a question: How does App A send a Node to App B if there is no connection between them in the first place? Firstly, in addition to sending a Node object from one process to another (as shown above) it is also possible to send a Ref object in a similar way. For example, assuming that there exists another App C, then App B can send the Ref (created at step 3 above) to App C. Once App C receives the Ref from App B it can use the Ref to send transactions to App A.
Secondly, Binder enables a special process to claim itself as the Context Manager with the BINDER_SET_CONTEXT_MGR ioctl and only one single process can hold the role. The Context Manager is a special Binder IPC endpoint always accessible at handle (Ref) 0 which serves as an intermediary to make Binder IPC endpoints discoverable by other processes.
For instance, a process Client 1 sends a Node (e.g. 0xbeef) to the Context Manager, which in turn receives a Ref (0xbeef). Then, another third process Client 2 initiates a transaction to the Context Manager asking for that Ref (0xbeef). Context Manager responds to the request by returning the Ref (0xbeef). Consequently, this establishes a connection between two processes as Client 2 can now send transactions to Client 1 using the Ref (0xbeef).
On Android, the ServiceManager process claims itself as the Context Manager during startup. System services register their Binder Nodes with the Context Manager to be discoverable by other Apps.
A client can include a Binder object (struct binder_object) in a transaction, which can be any of these:
| Name | Enum | Description |
|---|---|---|
| Node | BINDER_TYPE_BINDERBINDER_TYPE_WEAK_BINDER | A Node |
| Ref | BINDER_TYPE_HANDLEBINDER_TYPE_WEAK_HANDLE | A reference to a Node |
| Pointer | BINDER_TYPE_PTR | A pointer to a memory buffer used for transferring data |
| File Descriptor | BINDER_TYPE_FD | A file descriptor |
| File Descriptor Array | BINDER_TYPE_FDA | An array of file descriptors |
Before sending all Binder objects to the recipient, Binder must translate those objects from the sender’s context into the recipient’s context in the binder_transaction function:
static void binder_transaction(...)
{
...
// Iterate through all Binder objects in the transaction
for (buffer_offset = off_start_offset; buffer_offset < off_end_offset;
buffer_offset += sizeof(binder_size_t)) {
// Process/translate one Binder object
}
...
}
For example, consider a scenario where a client shares a file to another client by sending a file descriptor via Binder. To allow the recipient to access the file, Binder translates the file descriptor by installing a new file descriptor with the shared file in the recipient’s task process.
Note: Some objects are actually translated when the recipient reads the transaction - when
BINDER_WRITE_READioctl is invoked by the recipient - while others are translated at the moment of sending transaction by the sender - whenBINDER_WRITE_READioctl is invoked by the sender.
There exists a code path for error handling [1] when processing a transaction with an unaligned offsets_size. Notice that Binder skips the for-loop processing Binder objects, so buffer_offset remains 0 and is then passed to the binder_transaction_buffer_release function call [2] as an argument:
static void binder_transaction(..., struct binder_transaction_data *tr, ...)
{
binder_size_t buffer_offset = 0;
...
if (!IS_ALIGNED(tr->offsets_size, sizeof(binder_size_t))) { // [1]
goto err_bad_offset;
}
...
// Iterate through all Binder objects in the transaction
for (buffer_offset = off_start_offset; buffer_offset < off_end_offset;
buffer_offset += sizeof(binder_size_t)) {
// Process a Binder object
}
...
err_bad_offset:
...
binder_transaction_buffer_release(target_proc, NULL, t->buffer,
/*failed_at*/buffer_offset, // [2]
/*is_failure*/true);
...
}
binder_transaction_buffer_release is a function that undoes every side effect that Binder caused after processing Binder objects in the transaction. For example, closing the opened file descriptor in the recipient process’s task. In error handling cases, Binder must only clean up Binder objects that it has already processed before hitting an error. The failed_at and is_failure parameters in the function determine how many Binder objects Binder has to clean up.
Back to the error handling path of unaligned offsets_size where failed_at == 0 and is_failure == true. In this case, Binder calculates off_end_offset to be the end of the transaction buffer. Therefore, Binder cleans up every Binder object in the transaction. However, Binder did not process any Binder objects in the first place because it hit the error and skipped the for-loop which processes the Binder objects.
static void binder_transaction_buffer_release(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_buffer *buffer,
binder_size_t failed_at/*0*/,
bool is_failure/*true*/)
{
...
off_start_offset = ALIGN(buffer->data_size, sizeof(void *));
off_end_offset = is_failure && failed_at ? failed_at
: off_start_offset + buffer->offsets_size;
for (buffer_offset = off_start_offset; buffer_offset < off_end_offset;
buffer_offset += sizeof(size_t)) {
...
}
...
}
The reason for this logic is that the meaning of failed_at is overloaded: there are other parts of the code that use this logic to clean up the entire buffer. However, in this case we’ve hit this code path without processing any objects, which will introduce inconsistency in reference counting. In the following section we will demonstrate how to leverage this vulnerability to achieve a use-after-free of a Binder Node object and turn it into a privilege escalation PoC.
In a previously published exploit for CVE-2020-004, Blue Frost Security exploited the same cleanup process to achieve root privilege. However, they exploited a vulnerability that modifies the Binder objects within the transaction after Binder had processed it. They published a PoC to demonstrate their root privilege escalation on a Pixel 3 running kernel version 4.9.
We took inspiration from this past exploit to first achieve the same leak and unlink primitives in Binder. Because of some changes in the SLUB allocator’s caches in newer kernel versions, we used a different approach to perform use-after-free on the victim objects. We will explain those changes and how we overcame them in a later section.
A Node (struct binder_node) is a Binder object (struct flat_binder_object) in a transaction with the header type BINDER_TYPE_BINDER or BINDER_TYPE_WEAK_BINDER. Binder creates a Node internally when a client sends a Node to another client. Binder also manages several reference counters in the Node to determine its lifetime. In this section, we demonstrate how to leverage the vulnerability described above to introduce inconsistency in one of the reference counters of a Node object, which leads to freeing this object while having a dangling pointer to it and, thus, resulting in a use-after-free.
When the binder_transaction_buffer_release function iterates through all Binder objects in the buffer and encounters a Node with the header type BINDER_TYPE_BINDER or BINDER_TYPE_WEAK_BINDER, it calls the binder_get_node function to retrieve the binder_node that belongs to the recipient process’s context (proc) and has the Node ID equal to fp->binder ([1] in the listing below).
Then, it calls the binder_dec_node function to decrement one of its reference counters ([2] in the listing below). Suppose we have a Node in the transaction with the header type BINDER_TYPE_BINDER, then Binder calls binder_dec_node function with passing expressions strong == 1 and internal == 0 as function arguments.
static void binder_transaction_buffer_release(...)
{
...
for (buffer_offset = off_start_offset; buffer_offset < off_end_offset;
buffer_offset += sizeof(size_t)) {
...
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
...
// [1]
node = binder_get_node(proc, fp->binder);
...
// [2]
binder_dec_node(node, /*strong*/ hdr->type == BINDER_TYPE_BINDER, /*internal*/ 0);
...
} break;
...
}
...
}
Note: The terms Node and
binder_nodeare interchangeable, but the termbinder_nodeusually refers to the underlying Node data structure in Binder. The term Node is also used to refer to astruct flat_binder_objectin a transaction that has the header typeBINDER_TYPE_BINDERandBINDER_TYPE_WEAK_BINDER.
The binder_dec_node function calls binder_dec_node_nilocked to decrement one of the reference counters ([1] in listing below) of the binder_node. If binder_dec_node_nilocked returns true, the function will call binder_free_node to free the binder_node ([2] in listing below). That’s exactly the branch we want to be taken in order to achieve UAF.
static void binder_dec_node(struct binder_node *node, int strong /*1*/, int internal /*0*/)
{
bool free_node;
binder_node_inner_lock(node);
free_node = binder_dec_node_nilocked(node, strong, internal); // [1]
binder_node_inner_unlock(node);
if (free_node)
binder_free_node(node); // [2]
}
Note: There are many functions in Binder that has a suffix *locked which expects that the caller has acquired necessary locks before calling them. More details about all the suffixes can be found at the top of /drivers/android/binder.c code.
In the binder_dec_node_nilocked function, if strong == 1 and internal == 0, it decrements the local_strong_refs field in binder_node.
static bool binder_dec_node_nilocked(struct binder_node *node,
int strong /*1*/, int internal /*0*/)
{
...
if (strong) {
if (internal)
...
else
node->local_strong_refs--;
...
} else {
...
}
...
}
Thus, to trigger the vulnerability we can send a transaction with a Node object with the header type set to BINDER_TYPE_BINDER and the binder field set to the ID of the Node (struct binder_node) we want to decrement the value of its local_strong_refs reference counter. The diagram below shows a malicious transaction that exploits the vulnerability to decrement a reference counter in the Node 0xbeef of the recipient client two times. The transaction contains two Nodes (struct flat_binder_object) and an unaligned offsets_size.
The unaligned offsets_size cause Binder to take the vulnerable error-handling path in the binder_transaction function, which skips processing the two Nodes in the transaction. This exploits the binder_transaction_buffer_release function to clean up those two Nodes, which decrements the Node 0xbeef’s local_strong_refs twice – once for each of the 2 struct flat_binder_ojbect objects in the transaction.
Now, let’s analyze which conditions struct binder_node needs to satisfy to be freed in the binder_dec_node function (i.e. under what conditions binder_dec_node_nilocked returns true forcing binder_dec_node to free the binder_node). Based on the code fragment below, the binder_dec_node_nilocked returns true based on the values of several fields in the struct binder_node.
static bool binder_dec_node_nilocked(struct binder_node *node,
int strong /*1*/, int internal /*0*/)
{
...
if (strong) {
if (internal)
...
else
node->local_strong_refs--;
if (node->local_strong_refs || node->internal_strong_refs)
return false;
} else {
...
}
if (proc && (node->has_strong_ref || node->has_weak_ref)) {
...
} else {
if (hlist_empty(&node->refs) && !node->local_strong_refs &&
!node->local_weak_refs && !node->tmp_refs) {
...
return true;
}
}
return false;
}
To ensure that binder_dec_node_nilocked returns true after decrementing local_strong_refs, we have to pass a node that meets the following conditions:
// Reference counters in struct binder_node
local_strong_refs == 1 // before `binder_dec_node_nilocked` decrements it
local_weak_refs == 0
internal_strong_refs == 0
tmp_refs == 0
has_strong_ref == 0
has_weak_ref == 0
hlist_empty(&node->refs) == true
Thus, to free a binder_node object in the binder_dec_node function we must set up a binder_node that does not have any Refs referencing it and all reference counters are equal to zero except the local_strong_refs. Then, we can exploit the vulnerability to decrement the local_strong_refs and cause it to be freed by binder_free_node.
A simple way to set up a binder_node as such is as follows:
- Client A and Client B establish a connection between each other with the Node 0xbeef and Ref 0xbeef (refer to previous diagrams). The Node begins with
local_strong_refsequal to 1 because only the Ref object is referencing the Node. - Client B sends a transaction with the
target.handleset to0xbeef. Binder processes it, allocates abinder_bufferon the Client A’s side and copies the transaction data into the allocated buffer. At this moment, the Node’slocal_strong_refsis equal to 2 because the Ref object and the transaction are referencing the Node. - Client B closes the Binder file descriptor, which releases the Ref object and decrements the
local_strong_refsby 1. Now, the Node’slocal_strong_refgoes back to 1 because only the transaction is referencing the Node.
The diagram below illustrates the setup of a binder_node before and after exploiting the vulnerability to free it:
After freeing the binder_node by exploiting the vulnerability, this leaves a dangling pointer in the target_node of the binder_buffer. In the following sections we utilize this use-after-free multiple times to obtain the necessary primitives for our exploit to root an Android device.
First we obtain a limited leak primitive enabling us to leak 16 bytes (2 8-byte values) from the kernel heap. We built on top of this primitive to get next-stage unlink primitive enabling us to overwrite kernel memory with the attacker controlled data. Next, we leverage both leak and unlink primitives to obtain arbitrary kernel memory read primitive which we use to identify addresses of kernel structures we want to overwrite to finally get root privileges on the devices.
First, we exploit the vulnerability in the use-after-free read of a freed binder_node object in the binder_thread_read function. When a client performs a BINDER_WRITE_READ ioctl to read incoming transactions from Binder, Binder calls the binder_thread_read function to copy incoming transactions back to the userspace. This function copies two fields from the binder_node (ptr and cookie) into a transaction ([1] and [2]). Then, Binder copies the transaction back to userspace [3]. Therefore, we can cause an use-after-read to leak two values from the kernel heap memory.
static int binder_thread_read(...)
{
...
struct binder_transaction_data_secctx tr;
struct binder_transaction_data *trd = &tr.transaction_data;
...
struct binder_transaction *t = NULL;
...
t = container_of(w, struct binder_transaction, work);
...
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
trd->target.ptr = target_node->ptr; // [1]
trd->cookie = target_node->cookie; // [2]
...
}
...
if (copy_to_user(ptr, &tr, trsize)) { // [3]
...
}
...
}
The binder_node object is allocated from the kmalloc-128 SLAB cache and the two 8-bytes leaks are at offsets 88 and 96.
gdb> ptype /o struct binder_node
/* offset | size */ type = struct binder_node {
...
/* 88 | 8 */ binder_uintptr_t ptr;
/* 96 | 8 */ binder_uintptr_t cookie;
There can be an use-after-free in an unlink operation in the binder_dec_node_nilocked function [1]. However, there are also multiple checks before reaching the unlink operation.
static bool binder_dec_node_nilocked(struct binder_node *node,
int strong, int internal)
{
struct binder_proc *proc = node->proc;
...
if (strong) {
...
if (node->local_strong_refs || node->internal_strong_refs)
return false;
} else {
...
}
if (proc && (node->has_strong_ref || node->has_weak_ref)) {
...
} else {
if (hlist_empty(&node->refs) && !node->local_strong_refs &&
!node->local_weak_refs && !node->tmp_refs) {
if (proc) {
...
} else {
BUG_ON(!list_empty(&node->work.entry));
...
if (node->tmp_refs) {
...
return false;
}
hlist_del(&node->dead_node); // [1]
...
}
return true;
}
}
return false;
}
The unlink operation implemented in __hlist_del function basically modifies two kernel pointers to point to each other.
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
WRITE_ONCE(*pprev, next);
if (next)
WRITE_ONCE(next->pprev, pprev);
}
Without loss of generality it can be summarized as:
*pprev = next
*(next + 8) = pprev
To reach the unlink operation, we must reallocate the freed binder_node object with a fake binder_node object whose data we control. For that we can use a well-known sendmsg heap spray technique to allocate an object with arbitrary data on top of the freed binder_node.
Because there are multiple checks before the unlink operation, we must fill the fake binder_node with the right data to pass them. We must create a fake binder_node object with the following conditions:
node->proc == 0
node->has_strong_ref == 0
node->has_weak_ref == 0
node->local_strong_refs == 0
node->local_weak_refs == 0
node->tmp_refs == 0
node->refs == 0 // hlist_empty(node->refs)
node->work.entry = &node->work.entry // list_empty(&node->work.entry)
The last condition is tricky to satisfy because we must already know the address of the freed binder_node to calculate the correct &node->work.entry. Fortunately, we can use our leak primitive to leak a binder_node address before exploiting the vulnerability to free it. Here is how we can accomplish this.
A binder_ref object is allocated from the kmalloc-128 SLAB cache and contains a pointer to the corresponding binder_node object exactly at offset 88 (as you remember our leak primitive discussed above leaks two 8-byte values at offsets 88 and 96 during use-after-free read).
gdb> ptype /o struct binder_ref
/* offset | size */ type = struct binder_ref {
...
/* 88 | 8 */ struct binder_node *node;
/* 96 | 8 */ struct binder_ref_death *death;
Therefore, we can leak an address to a binder_node with the following steps:
- Exploit the vulnerability to free a
binder_node. - Allocate a
binder_refon top of the freedbinder_node. - Use the leak primitive to leak an address to a
binder_nodefrom thebinder_ref.
Once we leak the address of the freed binder_node object we have all the necessary data to set up our unlink primitive. After reallocating our fake binder_node with sendmsg, we send a BC_FREE_BUFFER binder command to free the transaction containing the dangling binder_node to trigger the unlink operation. At this point, we achieve a limited arbitrary write primitive – due to the implementation details of __hlist_del function we overwrite kernel memory either with a valid kernel pointer or with NULL.
The exploit for CVE-2020-0041 utilized the FIGETBSZ ioctl to obtain arbitrary read primitive. The FIGETBSZ ioctl copies 4 bytes of data corresponding to the s_blocksize member of struct super_block from the kernel back to the userspace as shown in the listing below at [1].
static int do_vfs_ioctl(struct file *filp, ...) {
...
struct inode *inode = file_inode(filp);
...
case FIGETBSZ:
...
return put_user(inode->i_sb->s_blocksize, (int __user *)argp); // [1]
...
}
ioctl(fd, FIGETBSZ, &value); // &value == argp
The diagram below shows the location of the s_blocksize field as referenced by struct file and struct inode structures.
We can perform an unlink write to modify the inode pointer to point to a struct epitem that we know the address of. As we can directly control the event.data field (located at the offset of 40 bytes from the beginning of the structure) in the struct epitem with epoll_ctl to point it to anywhere in kernel address space, then we can easily modify the i_sb field (also located at the offset 40) shown above with any arbitrary value.
Then, we can use the FIGETBSZ ioctl and epoll_ctl as our arbitrary read primitive to read a 4-byte value from anywhere in the kernel address space. BUT, we must first know the kernel addresses of a struct file and a struct epitem objects.
The struct epitem contains two kernel pointers (next and prev) at offsets 88 and 96 correspondingly.
gdb> ptype /o struct epitem
/* offset | size */ type = struct epitem {
...
/* 88 | 16 */ struct list_head {
/* 88 | 8 */ struct list_head *next
/* 96 | 8 */ struct list_head *prev;
} fllink;
These two kernel pointers (next and prev) form a linked list of struct epitem objects. The head of the linked list is located at struct file.f_ep_links. When we use the leak primitive to leak those kernel pointers back to the userspace, one of those pointers will point to a struct file object.
Allocating a struct epitem on top of the freed binder_node was straightforward in the previous exploit for CVE-2020-0041 targeting kernel version 4.9. Both struct epitem and binder_node are allocated from the same kmalloc-128 SLAB cache due to cache aliasing and the kmalloc-128 SLAB cache works in a FIFO manner. Therefore, after freeing the binder_node, we could allocate a struct epitem from the same memory location where the binder_node was.
Cache aliasing is a kernel feature which merges multiple SLAB caches into one single SLAB cache for efficiency purposes. This happens when those SLAB caches hold similar size objects and share similar attributes. More details on cache aliasing can be found in Linux kernel heap feng shui in 2022 blog.
In kernel version 5.10, a commit added the SLAB_ACCOUNT flag to the eventpoll_epi SLAB cache, so the eventpoll_epi and kmalloc-128 no longer share the same SLAB cache. In other words, a struct epitem is no longer allocated from the kmalloc-128 SLAB cache, which prevents us from allocating it on top of the freed binder_node immediately.
Cross-cache attack is a technique to allocate an object on top of another object that is allocated from a different cache. This is possible because there are multiple levels of memory allocators in the kernel and caches from the same level share the same memory allocator higher in their hierarchy. Caches in the SLUB allocator (kmem_cache) acquire a page from the page allocator and use them as a slab. If a kmem_cache releases a page back to the page allocator, another kmem_cache that requires additional memory during allocation will acquire it.
Notes: The page allocator is a buddy allocator which has caches for different orders of contiguous free pages. Different
kmem_caches use different numbers of contiguous pages as its slab. Fortunately, bothkmalloc-128andeventpoll_epikmem_caches use order-0 (2^0 = 1) page as a slab. Therefore, we do not have to groom the page allocator when performing a cross-cache attack and we can safely assume that the page allocator acts in a FIFO manner for every page allocated from and released to it.
The diagram below shows how a struct epitem can be allocated from the same memory region that was used by a previously freed binder_node.
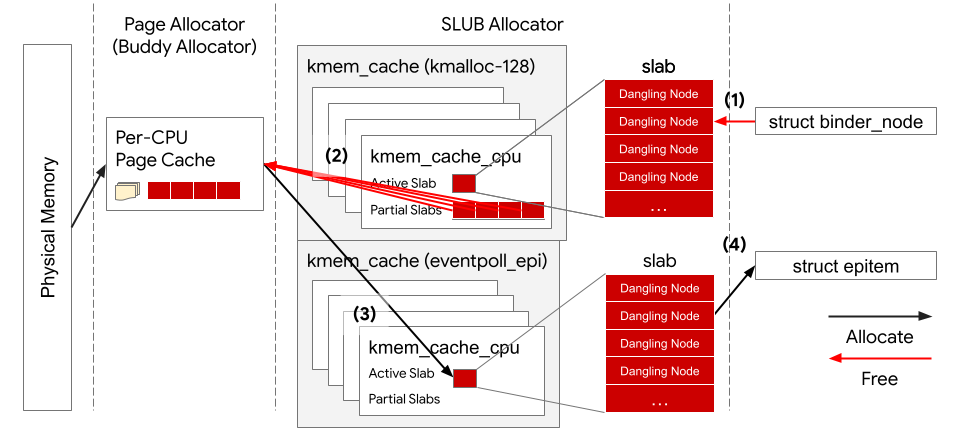
To perform a cross-cache attack, we must release a slab (a 4K page) from the kmalloc-128 back to the page allocator’s per-cpu page cache, so it can be allocated to eventpoll_epi. Each slab in the kmalloc-128 and eventpoll_epi is a 4K page and can hold 32 kernel objects (4096 / 128).
To have control over one whole slab, we must allocate 32 binder_objects. Then, we exploit the vulnerability to release all binder_nodes at once and leave dangling pointers pointing to them. However, SLUB allocator does not immediately release the page of the empty slab back to the page allocator, but puts it on the kmalloc-128 cache’s partial list and makes it frozen (by setting struct page.frozen field).
Notes: SLUB allocator uses the
struct pageof the slab to store metadata, such as the number of in-use objects, the next page in the partial list and etc..
Every kmem_cache holds a number of slabs in the partial list, which can be empty or partially-empty, before releasing the empty slabs back to the page allocator. The SLUB allocator tracks the number of free slots in the partial list in the page of the first slab on the list (struct page.pobjects). When the value of pobjects field is larger than the value of kmem_cache.cpu_partial field, the SLUB allocator unfreezes and releases every empty slab back to the page allocator. The set_cpu_partial function determines the value of kmem_cache.cpu_partial and it is 30 for the kmalloc_128.
However, as it turned out it’s not sufficient to have 30 empty slots in the partial list to get our empty slabs be released back to the page allocator. At the moment of working on PoC there was an accounting bug in the SLUB allocator that causes the pobjects to keep track of the number of slabs on the partial list instead of empty slots. Therefore, the SLUB allocator starts releasing empty slabs back to the page allocator when the kmalloc-128 has more than 30 slabs in the partial list.
In our exploits, we allocate 36 * 32 (number of slabs * number of objects in a slab) binder_nodes and release them all at once. Then, we allocate more than 32 struct epitems to use up all the empty slots on the eventpoll_epi’s partial lists, so eventpoll_epi will allocate new pages from the page allocator.
Finally, we use the leak primitive on all dangling nodes to read the values of those two fields at offset 88 and 96. If we have successfully allocated a struct epitem on top of an already freed binder_node, we will find kernel addresses in those fields and one of them is the kernel address of a struct file.
We want to fill the whole kmalloc-128 slab with binder_nodes, so we can create dangling pointers to every object in the slab by exploiting the vulnerability, but there is a challenge.
slab
+---------------+
| *binder_node* |<---- dangling pointer
+---------------+
| *binder_node* |<---- dangling pointer
+---------------+
| ... |
+---------------+
When we send a transaction, Binder also allocates other kernel objects from the kmalloc-128 cache, such as the struct binder_buffer object. The binder_buffer object holds information about the transaction buffer and a pointer to a binder_node owned by the recipient client’s binder_proc. Exploiting the vulnerability turns that pointer to a dangling pointer to the freed binder_node.
slab
+---------------+
| ... |
+---------------+
| binder_buffer |----+
+---------------+ | dangling pointer
| *binder_node* |<---+
+---------------+
| ... |
+---------------+
However, we cannot free this binder_buffer yet because we need it to trigger the use-after-free for the leak and unlink primitives. Therefore, we must ensure the binder_buffer cannot be allocated from the same kmalloc-128 slab as the binder_nodes.
Binder implements its own memory allocator to allocate memory for every incoming transaction and map them to the recipient’s mapped memory map. The memory allocator employs the best-fit allocation strategy and uses the binder_buffer object to keep track of all allocated and free memory regions. When allocating a new transaction buffer, it searches for a free binder_buffer of the same size to reuse. If none is available, it splits a larger free binder_buffer into two: one with the requested size and another with the remaining size.
To prevent Binder from allocating a new binder_buffer for every transaction, we can allocate many free binder_buffers in advance by causing memory fragmentation. We can achieve that by sending multiple transactions of varying sizes and selectively releasing some of them. Consequently, this process creates gaps within the memory allocator, which results many free binder_buffer available for reuse in future transactions.
Binder buffer allocator
+-----------------+----------+-----------------+----------+---------+
| free (24) | used (8) | free (24) | used (8) | ... |
+-----------------+----------+-----------------+----------+---------+
Here is a video demonstrating the cross-cache attack:
To obtain root privileges, we perform the following steps:
- Use the arbitrary read primitive to find our process’s
task_structandcredstructures.
struct binder_node *node;
struct binder_proc *proc = node->proc;
struct task_struct *task = proc->tsk;
struct task_struct *cred = task->cred;
- Overwrite all the ID fields in the
struct credobject with 0 (the UID for root). - Disable SELinux by overwriting
selinux.enforcingfield with 0. - Enable
TIF_SECCOMPin the current task flag and overwrite the seccomp’s mask with 0 to bypass seccomp.
Although we do not need an arbitrary write primitive to achieve root privilege in our PoC, we would like to provide information on how to obtain write-what-where primite for the reference.
Our unlink primitive can write at any arbitrary address writeable in the kernel, but it can only write 0 or a value which is valid (i.e. writeable) kernel address. To achieve a more powerful arbitrary write (write-what-where), we chose to exploit the pointer field buf in the struct seq_file object based on the technique presented in Typhoon Mangkhut exploit chain by 360 Alpha Lab (slides).
struct seq_file {
char *buf;
...
};
The struct seq_file is used by files implemented with the Linux’s seq_file interface, for example /proc/self/comm. When opening the /proc/self/comm file, the kernel creates a struct seq_file and calls the comm_open function. The comm_open passes the comm_show function to the single_open function to define what string to show when the file is read.
// fs/proc/base.c
static int comm_open(struct inode *inode, struct file *filp)
{
return single_open(filp, comm_show, inode);
}
The comm_show copies the current task name into the seq_file->buf buffer ([1] in the listing below).
// fs/proc/base.c
static int comm_show(struct seq_file *m, void *v)
{
...
proc_task_name(m, p, false);
...
}
// fs/proc/array.c
void proc_task_name(struct seq_file *m, struct task_struct *p, bool escape)
{
char *buf;
size_t size;
char tcomm[64];
...
// `tcomm` is filled with the current task name
...
size = seq_get_buf(m, &buf); // buf = m->buf
if (escape) {
...
} else {
ret = strscpy(buf, tcomm, size); // [1]
}
}
We can open the /proc/self/comm file two times to allocate two instances struct seq_file in the kernel. Then, we use the unlink primitive to overwrite struct seq_file->buf field in the first instance to point to the address of struct seq_file->buf field in the second instance.
As a result, this enables us to overwrite the struct seq_file->buf field in the second instance to point to any arbitrary kernel address by changing the current task name to the 8-byte value of the target address and calling lseek on the first seq_file’s file descriptor ([2] in the listing below). Calling lseek on the file descriptor will trigger the comm_show function leading to overwriting struct seq_file->buf field in the second instance of the structure with the target address.
// [2] Point `seq_file->buf` to arbitrary kernel address
prctl(PR_SET_NAME,"\xef\xbe\xad\xde\xff\xff\xff\xff\0", 0, 0, 0);
lseek(comm_fd1, 1, SEEK_SET); // comm_fd1 = First seq_file's file descriptor
The diagram below shows the layout of the instances of struct seq_file with struct seq_file->buf field pointing at the attacker-chosen address.
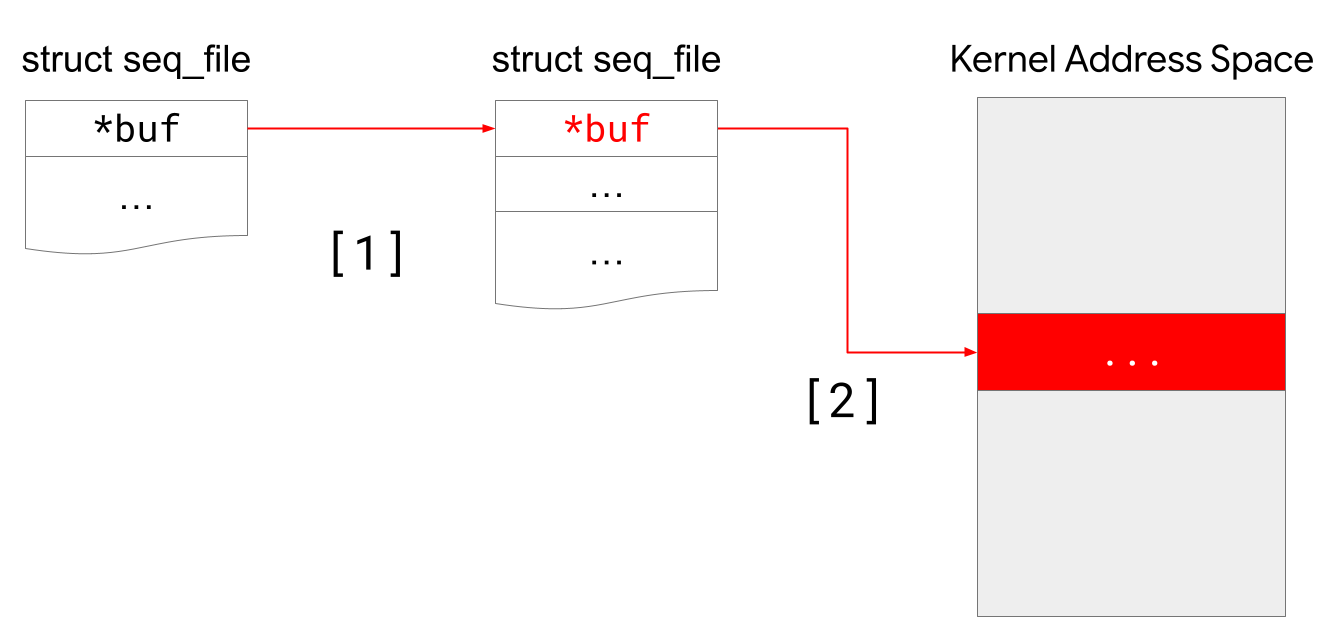
Then, we can perform similar actions on the second seq_file’s file descriptor to write with data we control by setting the current task name. As a result, this gives us a more powerful arbitrary write (write-what-where) primitive in kernel memory.
Let’s examine the 4 reference counters of a struct binder_node.
The local_strong_refs and local_weak_refs keep track of the number of Nodes in all transactions that reference the Node. Remember the Node in a transaction (struct flat_binder_object) has a different data structure from the Node (struct binder_node) that Binder creates internally for bookkeeping. Binder ensures that every binder_node does not go away when there are Nodes in transactions that have references to it.
After opening a Binder device file, we call mmap to provide a shared memory map that Binder uses to store data for incoming transactions. Binder implements a buffer allocator to manage that shared memory map, which allocates a struct binder_buffer to occupy a part of the memory map to store an incoming transaction data. The target_node field in the struct binder_buffer references the binder_node that belongs to the receiving client, which increments that binder_node’s local_strong_refs refcount.
The internal_strong_refs keep tracks of how many Refs other clients have that are referencing the Node.
The diagram below illustrates a scenario where Client A has an incoming transaction that contains two Nodes and Client B has a Ref 0xbeef (binder_ref) that references Client A’s Node 0xbeef (binder_node). Most importantly, it highlights how those data structures increment the reference counters of Node 0xbeef.
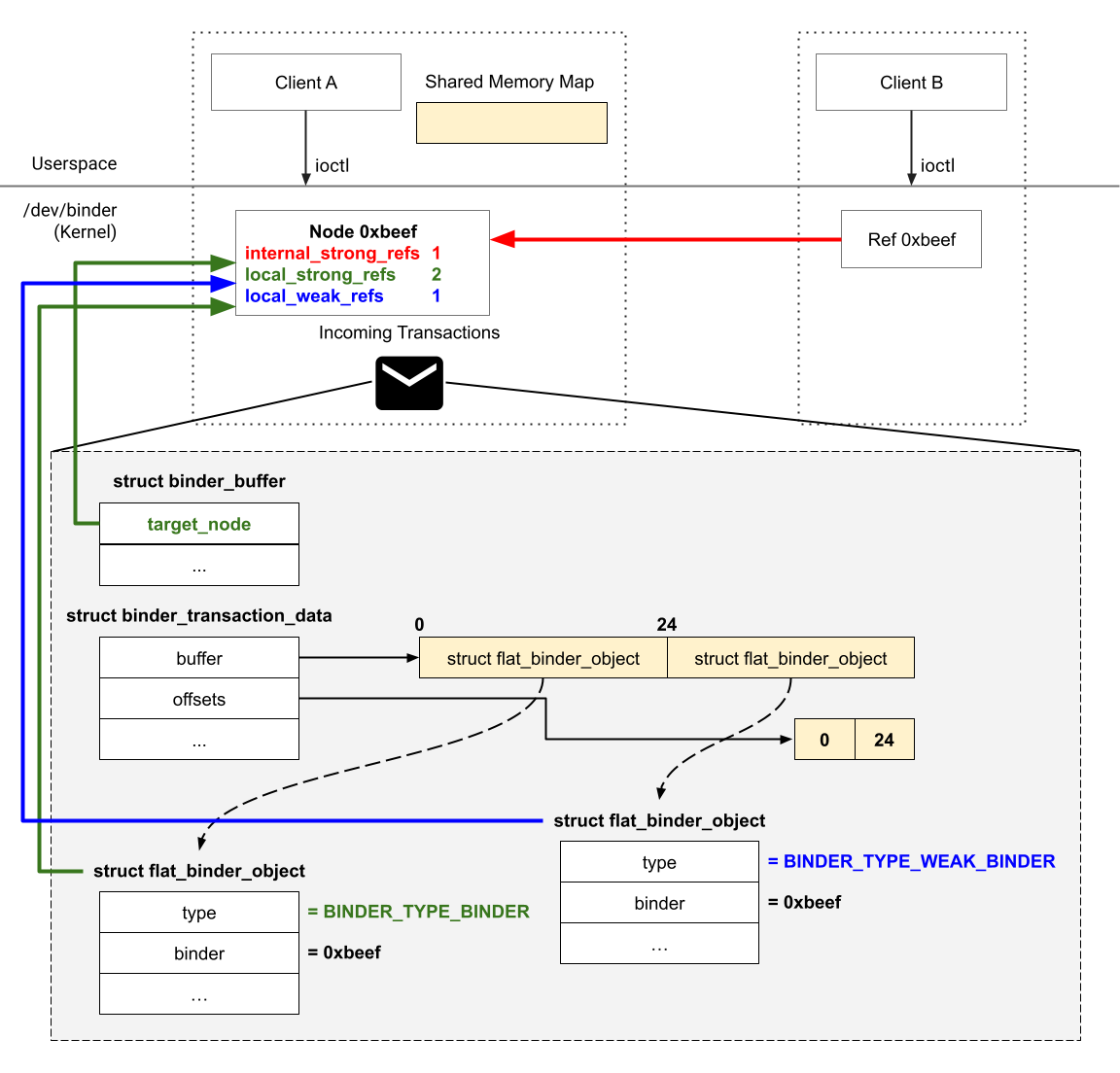
When Binder assigns a variable to a pointer to a binder_node, it uses the tmp_refs to keep the binder_node alive as long as the pointer is used within its scope. The code below shows a basic example:
struct binder_node *node = ...;
binder_inc_node_tmpref(node);
// Access `node` safely
binder_dec_node_tmpref(node); // `node` can no longer be used after this.
Otherwise, there can be race conditions.
Binder also sets the has_strong_ref and has_weak_ref flags when there is at least one Ref that references the binder_node.
The binder_node->refs points to the head of a list of Refs.
The issue described in this blog has been remediated in two Android Security Bulletins:
- CVE-2023-20938 in 2023-02-01
- CVE-2023-21255 in 2023-07-01
CVE-2023-20938 was initially addressed in the February 2023 Android Security Bulletin by back-porting a patch to the vulnerable kernels. However, further analysis reveals that the patch did not fully mitigate the underlying root cause and it was still possible to reach the bug, although, through a different path. As a result, a new CVE-2023-21255 was assigned and the root cause was fully mitigated in the July 2023 Android Security Bulletin.
Special thanks to Carlos Llamas, Jann Horn, Seth Jenkins, Octavian Purdila, Xingyu Jin, Farzan Karimi, for their support with technical questions and for reviewing this post.
For technical questions about content of this post, contact androidoffsec-external@google.com. All press inquiries should be directed to press@google.com.